Azure Databricks
/What is Azure Databricks?
Azure Databricks is an Apache Spark based analytics platform optimised for Azure. Designed in collaboration with the founders of Apache Spark, Azure Databricks is deeply integrated across Microsoft’s various cloud services such as Azure Active Directory, Azure Data Lake Store, Power BI and more.
Azure Databricks makes it easier for users to leverage the underlying Apache Spark engine by providing managed Spark clusters that can be associated with web-based workspaces (i.e. Spark-as-a-Service). It is these interactive workspaces that enable collaboration among data scientists, data engineers, and business analysts, to develop Spark applications and ultimately derive value out of data.

History
Getting Started
The quickest way to get started is by spinning up an Azure Databricks service within your Azure subscription and launching directly into a workspace.
1. Log in to the Azure Portal.
2. Navigate to Create a Resource > Analytics > Databricks.
3. Populate the Azure Databricks Service dialog with the appropriate values and click Create.
4. Once the workspace has been deployed, navigate to the resource and click Launch Workspace.
Note: While most of the required fields are fairly straightforward, the choice between Standard and Premium pricing tiers may be less obvious. While it is important to keep in mind that these things are typically subject to change, at this point in time the primary difference between the two is the ability to enforce Role Based Access Control for Notebooks, Clusters, Jobs, and Tables. In the initial instance, I suggest starting with the Premium trial.

User Interface
Once you have launched into an Azure Databricks workspace, the next thing to do is orient yourself with the user interface. Click through the gallery to get a feel for the layout and various screens.
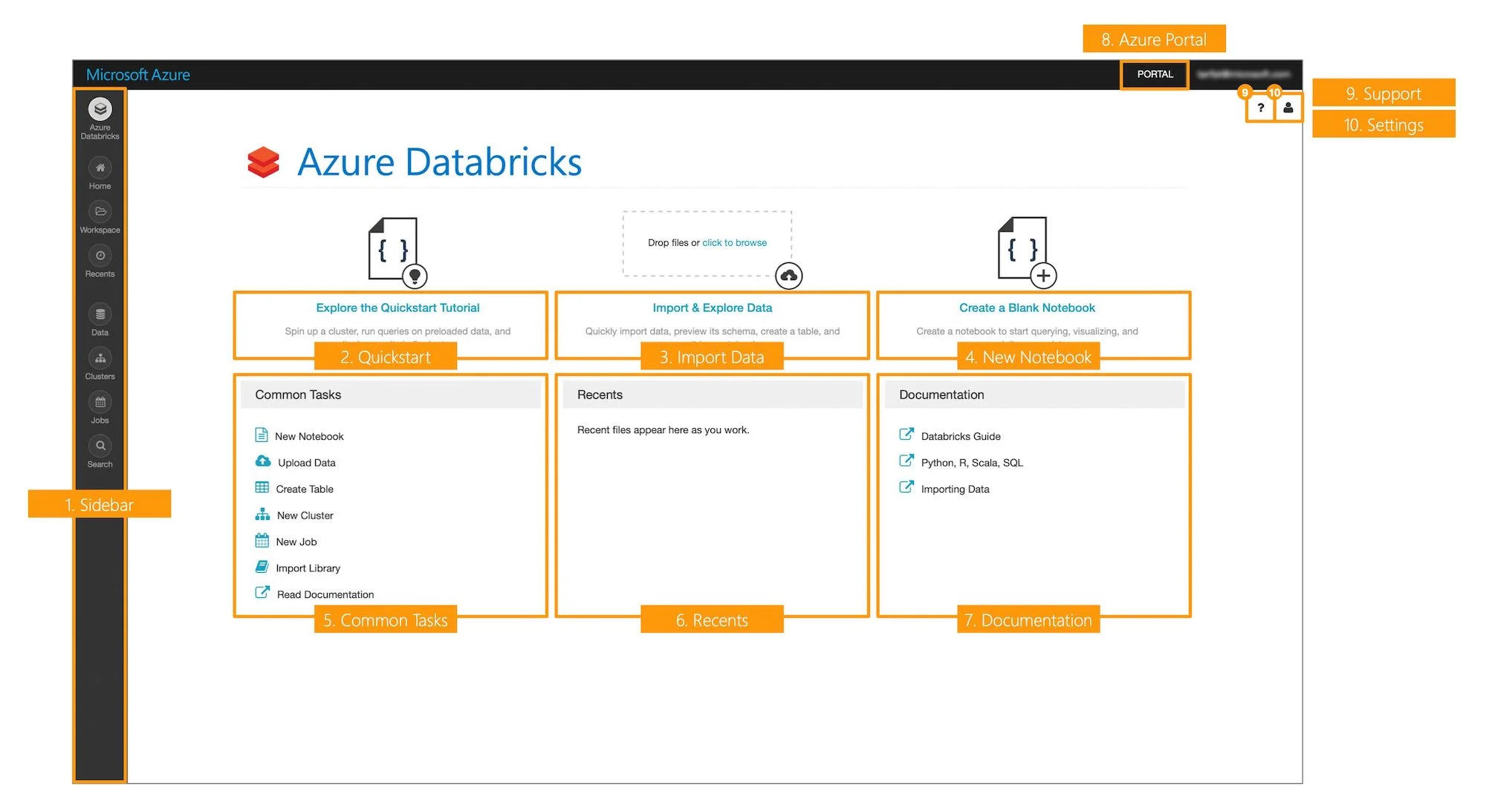




Concepts
Below is a list of some of the key Azure Databricks concepts.
Workspace
A workspace contains all of your organisation’s Databricks assets.
Within a workspace, you can create three types of objects: Notebooks, Libraries, and Folders.
By default, all content within a workspace is available to all users with the exception of a users own private directory.
A Databricks workspace has three special folders: Workspace (root folder), Shared, and Users. These folders cannot be deleted, moved, or renamed.

Notebook
A notebook is an interactive computational environment where users can combine runnable code (Python, SQL, Scala, R) and rich narrative text (via Markdown syntax) to facilitate various data workloads (e.g. data exploration, ETL pipelines, machine learning). In the context of Databricks, a notebook is a collection of runnable cells, allowing users to author and run Spark applications.

Cluster
A set of computation resources (Azure Linux VMs) that can be associated with a Notebook or Job in order to run Spark application code. While clusters are launched and the individual components are visible within an Azure subscription, the end-to-end lifecycle is managed via the Databricks portal.

Job
A way of running Spark application code either on-demand or on a scheduled basis. A job encapsulates the task that needs to be executed (Notebook or JAR), an association to a cluster (new or existing), and an option to specify a schedule in which the job will run.

Databricks File System (DBFS)
The Databricks File System is an abstraction layer on top of Azure Blob Storage that comes preinstalled with each Databricks runtime cluster. It contains directories, which can contain files and other sub-folders. Note: Since data is persisted to the underlying storage account, data is not lost after a cluster is terminated. Data can be accessed using the Databricks File System API, Spark API, Databricks CLI, Databricks Utilities (dbutils), or local file APIs.

Databricks Runtime
The set of core components that run on the clusters managed by Databricks. Consists of the underlying Ubuntu OS, pre-installed languages and libraries (Java, Scala, Python, and R), Apache Spark, and various proprietary Databricks modules (e.g. DBIO, Databricks Serverless, etc). Note: GPU and Machine Learning variants include additional pre-installed libraries geared towards data science.

Next Steps
Exploring the Quickstart Tutorial notebook (available directly from the Databricks main screen) is a great first step in further familiarising yourself with the Azure Databricks platform. Note: Before you can run the notebook you will need to create a cluster and associate that cluster to the notebook so that it has access to a computational resource for processing.
Create a Cluster
Navigate to the ‘Create Cluster’ screen (either via the Azure Databricks main screen or Clusters > Create Cluster). Since the majority of defaults are sensible, we will make the following minimal changes.
Provide a Cluster Name (e.g. MyFirstCluster).
Uncheck Enable Autoscaling.
Change the number of Workers to 1.
Click Create Cluster.

Once the cluster is in a Running state, return back to the Azure Databricks main screen and click Explore the Quickstart Tutorial. Behind the scenes, this will create a persisted version of the notebook within your private workspace (you can check this by opening the workspace panel and looking inside your user directory).
Attach and Run
In order to execute the runnable code within each of the notebook cells, we need to attach our notebook to the recently created cluster.
Click Run All.
A prompt will inform you that the notebook is currently not attached to a cluster, click Attach and Run.
That’s it. The cluster will work its way through each of the runnable cells in sequence. Each cell is able to leverage the results of the work done prior. The pop-up notifications will indicate which cell is actively being worked on until the notebook is completely processed.

By this point, you should have a basic understanding of Azure Databricks and some of the key concepts. For continued learning and points of reference, check out the list of resources below.
Resources
Azure Databricks Documentation - Microsoft Docs
Azure Databricks Documentation - (Supplementary)
Databricks Resources (eBooks, Example Notebooks, Whitepapers, etc)