Data Lakehouse
/1. What is a Data Lakehouse?
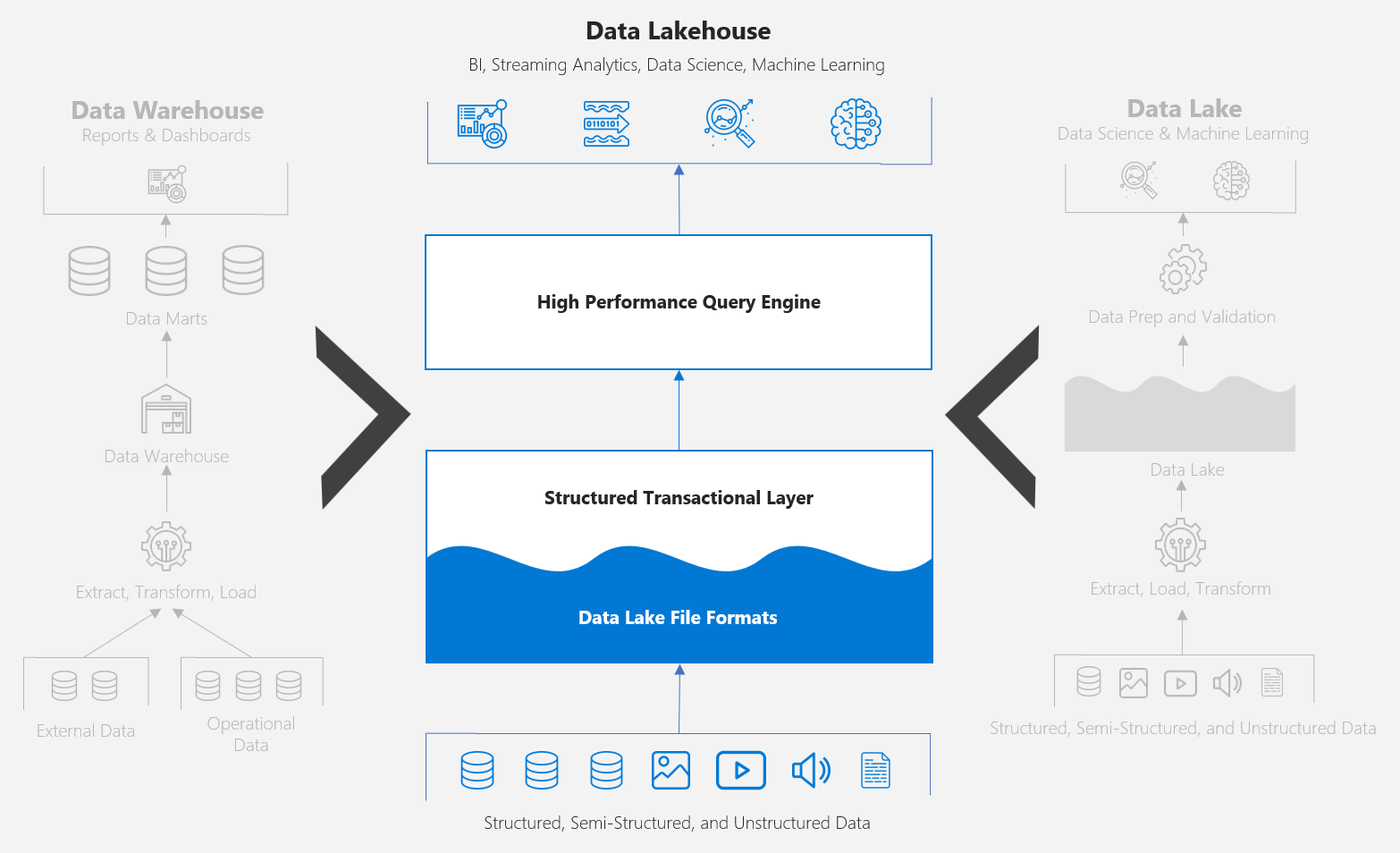
The data lakehouse is a data architecture pattern that brings elements of the data warehouse to the data lake, enabling a broader set of analytical workloads to coexist on a unified platform. A data lakehouse is not a new product or service per se, but rather an evolution of the data lake paradigm, made possible due to recent technology breakthroughs such as Apache Hudi, Apache Iceberg and Delta Lake, that have brought warehouse-like capabilities such as ACID transaction support, schema evolution, and time travel, to the data lake.
While the "data lakehouse" phrase itself is not new, Databricks is largely credited for helping spark mainstream adoption of the term since the blog post What is a Lakehouse? posted back in January 2020, followed by the publication of their research paper Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores in August 2020.
2. History of Data Architectures
Data Warehouse
The concept of data warehousing dates back to the late 1980s, designed to be a centralized repository of structured data from one or more disparate sources. The data warehouse is optimized for high performance, concurrency, and reliability, serving the needs of information consumers seeking to glean actionable insights through business intelligence tools, SQL clients, and other analytical applications.
While data warehouses have and continue to evolve in an attempt to cater for a variety of data types (semi-structured and unstructured) and a growing set of use cases such as big data, real-time streaming, and machine learning, other technologies would eventually emerge, better suited to handling these types of workloads.
Data Lake
The concept of data lakes dates back to the early 2010s, designed to be a repository for any type of data (structured, semi-structured, and unstructured), ingested in its original format (e.g. CSV, JSON, Binary) without the need to define data structures and schemas upfront (schema on read), atop of low-cost, highly durable, and highly scalable object storage such as Azure Data Lake Storage Gen2, Amazon S3, and Google Cloud Storage.
While data lakes have been ideal for data science and machine learning workloads with open APIs for direct file access, the lack of critical features such as transaction support, enforcement of data quality, and poor performance, meant customers would need to load subsets of data into the Data Warehouse to serve BI and SQL-based solutions, leading to a common two-tier data architecture.
| Data Warehouse | Data Lake | Data Lakehouse | |
|---|---|---|---|
| Cost | $$$ | $ | $ |
| Data Format | Closed | Open | Open |
| Data Type | Structured | Any | Any |
| Data Integrity | High | Low | High |
| Data Quality | High | Low | High |
| Performance | High | Low | Medium |
| Workloads | BI, SQL | Data Science, Machine Learning | BI, SQL, DS, ML |
Note: The comparison table is an over generalization intended to convey some of the key differences and similarities between the data architecture patterns. For example, while it is true that traditional data warehouses have historically only dealt with structured data, modern data warehouses have evolved to work with semi-structured data formats such as JSON, albeit limited support.
3. Data Lake Challenges
Prior to the availability of modern data lake table formats, data lakes have historically lacked certain critical features needed to facilitate the broader spectrum of data workloads.
Data Reliability
The lack of ACID transaction support meant that data lakes fell short compared to the level of consistency and integrity offered by other systems. For example, we are writing data into the data lake, a hardware or software failure occurs mid-stream, and the job does not complete. In this scenario, we would need to spend time and energy to check and delete for any corrupted data, then reprocess the job.
Data Quality
One of the key benefits of the data lake is the ease of which data can be ingested with the ability to stipulate data models and definitions after the fact (“schema-on-read” as opposed to “schema-on-write”). While this provides a level of flexibility for data engineers loading data into the data lake, it can lead to unexpected values being written to tables not matching downstream schema expectations, resulting in a degradation of data quality, and ultimately complexity being pushed down to the end user.
Performance
As data in the data lake increases, it becomes increasingly challenging for traditional query engines to derive great performance and meet the needs of latency sensitive applications. Bottlenecks can derive from non-optimized file sizes and layouts, improper data indexing and partitioning, lack of caching capabilities, and while data lakes have been accessible to BI and SQL-based applications, SQL connectors have historically been 2nd-class citizens on these platforms.
4. Rise of the Modern Data Lake Table Formats
Data lake table formats provide a layer of abstraction across files in the data lake, enabling one or more files to be represented as a logical dataset, which can be queried using SQL-like expressions commonly supported by a wide variety of tools. While Apache Hive was one of the original data lake table formats available, other table formats have since emerged, bringing critical warehouse-like capabilities to the data lake.
Apache Hudi, Apache Iceberg, and Delta Lake are currently three of the most popular data lake table formats available as open-source solutions. All three take a similar approach by establishing a metadata layer on top of data lake file formats (e.g. Parquet) to provide features such as:
ACID Transactions
Schema Evolution / Validation
Time-Travel
DML Operations (INSERT, UPDATE, DELETE, MERGE)
| Original Developer | 1st Open Commit | Governance | GitHub | Slack | |
|---|---|---|---|---|---|
| Apache Hudi | Uber | December 2016 | Apache Software Foundation | 🔗 | 🔗 |
| Apache Iceberg | Netflix | December 2017 | Apache Software Foundation | 🔗 | 🔗 |
| Delta Lake | Databricks | April 2019 | Linux Foundation | 🔗 | 🔗 |
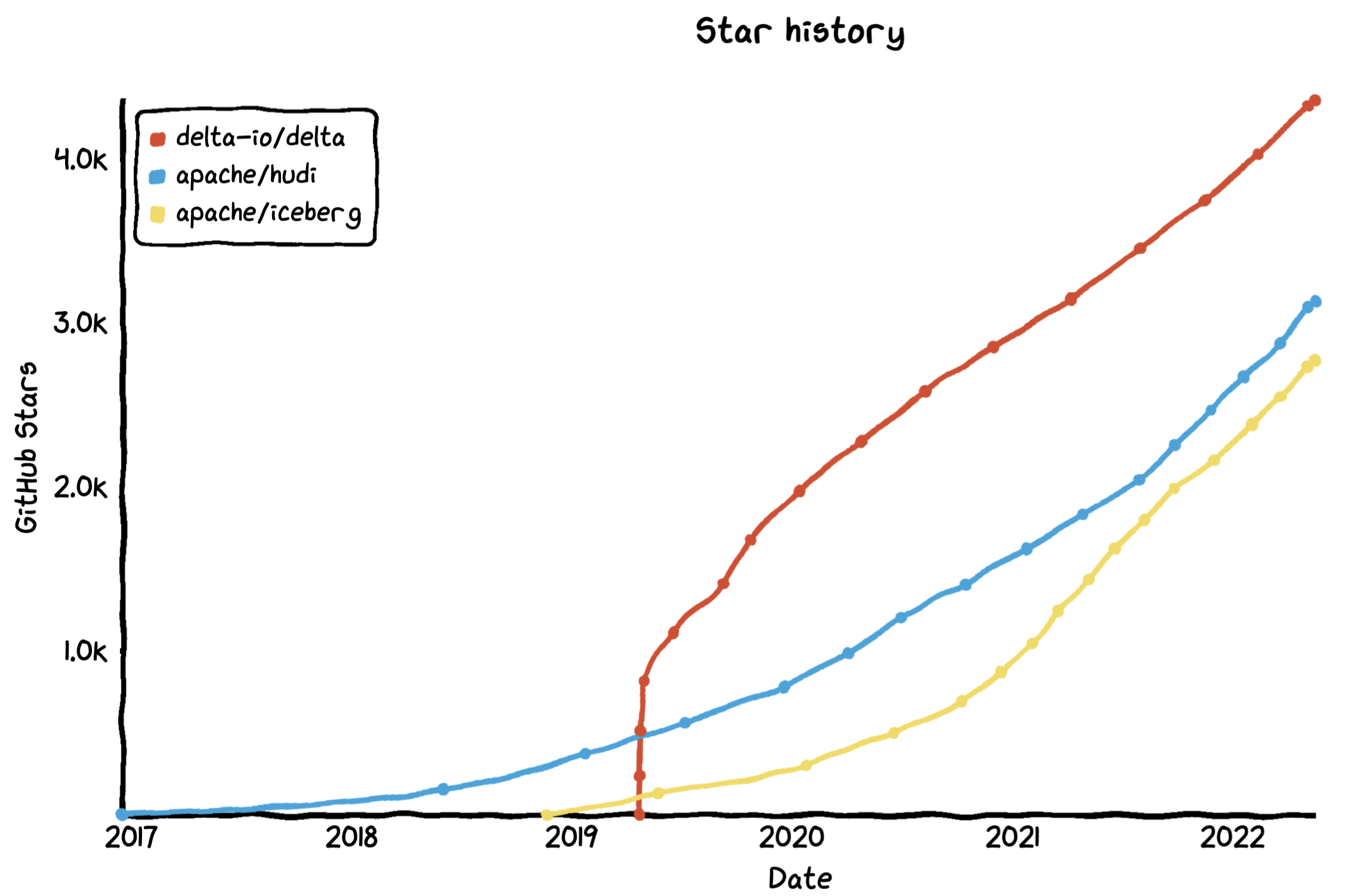
Despite Apache Hudi and Apache Iceberg benefiting from first mover advantage, Delta Lake appears to have gained the most momentum of the three formats. The image below is a graph of the GitHub star count as an indicative metric of adoption. Delta Lake surpassing the two other formats in a relative short amount of time, with growing interest across all three projects since late 2019.
5. Ingredients of a Data Lakehouse
While technologies such as Delta Lake are critical to materialising the promise of a Data Lakehouse, it is the integration with the rest of the rest of the data stack - data storage formats, processing engines, and query interfaces, that provide the end-to-end ability to facilitate the broad range of analytical workloads.

The graphic on the left illustrates example components that could be used in a data lakehouse architecture.
Note: This image is not intended to be a comprehensive list. Support matrices within the relevant vendor documentation will reveal that some of these components are not compatible with one another, therefore mileage will vary depending on business requirements.
Data
Structured, Semi-Structured, Unstructured
Data Lake Storage Formats
Apache Avro, Apache ORC, Apache Parquet
Data Lake Table Formats
Delta Lake, Apache Hudi, Apache Iceberg
Query Engines
Apache Spark, Apache Hive, Apache Flink, etc
Query Interfaces
Azure Synapse Analytics, Databricks, Amazon Athena, etc
Workloads
BI, Streaming Analytics, Data Science, Machine Learning, etc
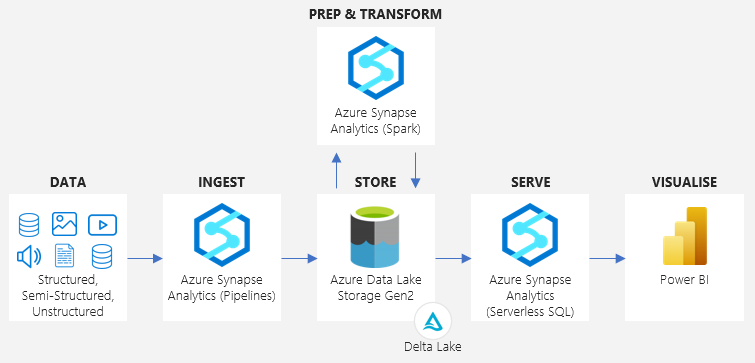
6. Example Architecture
An example of the data lakehouse pattern on Azure below, using services such as Azure Synapse Analytics, Azure Data Lake Storage Gen2, and Power BI.
Data Flow
Azure Synapse Analytics pipelines extract data (structured, semi-structured, unstructured) from various sources, and load this data to be persisted in its raw form (CSV, JSON, etc) in Azure Data Lake Storage Gen2.
Azure Synapse Analytics Spark (Notebooks or Data Flows) can then subsequently clean, transform, and enrich the data, with the resultant dataset being written back to Azure Data Lake Storage Gen2 as a Delta Lake table.
Azure Synapse Analytics serverless SQL can be used to query the Delta Lake tables directly as well as providing a logical abstraction layer through the creation of Delta Lake views.
Finally, Power BI can connect to the Azure Synapse Analytics serverless SQL endpoint to query and visualise data, making reports and dashboards available to end consumers.